Top 50 at Ironman in 3 years of training
July 2021 I needed a new sports challenge after years practicing strength training. I wanted a sport that is polyvalent and that I can do by myself. So I choose triathlon, it is cardio based, and has 3 sports and you train wherever you want when you want.
Before I start, I need to say that I did 1 year of running 10 years ago, I was training about one and half day a week and was pretty strong (I did 35'24 at a 10k). So yeah I have pretty good genetics regarding cardio. But I didnt do any endurance training for 10 years and I was restarting from scratch. The goal is not to say that everyone can do what I've done, but more to describe all the decisions I have taken and what are the weeks you need to have to do that kind of things
My first running session I didnt manage to run more than 40 minutes and I had to walk for sometimes. My body was a machine, I was full of muscles, but I was heavy and I had no cardio. My knees were hurting.
When I set myself an objective I always follow the same strategy. I want the objective to be long term (you cant be competitive if you give yourself a short timerange), I want the objective to be very difficult to achieve (people experts of the field need to tell you this is impossible, and I also need to beleive there is max 50% of change I will make it), and I want the goal to be at the edge of pro level and best amateurs.
So I choose to do 9h at an Ironman. This is very very far from a pro level, average pro can do 8h and the best pro can do 7h30, but this is still competitive, usually 9h at an ironman will make you qualify for the world championship.
Ironman is a triathlon with 3.9km (2.4mile) of swimming then 180km (112mile) of cycling and 42km (26 mile) of running. (In reality the distances vary from ironman to ironman, so these distances are not really respected). The terrain also varies, sometimes you swim in a lake, sometimes in the sea, sometimes in the ocean, sometimes in canal, sometimes it is cold, sometimes it is hot. All these factors will influence the time the same athlete will need to complete the swim. Same things with bike, sometimes it is super flat, sometimes it is flat with 2 loops of the same circuits, sometimes it is hilly, sometimes it is a moutain stage. And finally the same is true for running: warm, hot, hilly, flat.
I choose to do the Nice Ironman, I'm french, my parents live in Nice, and I like when it there are some mountain on the bike. My time of 9h in Nice is impossible, Nice has 2300m of positive elevation gain, if you compare the time of best pros between a mostly flat ironman and nice it is about 30minutes more. (Lange 2023 (Nice) : 8:10, Lange (2024) Kona : 7:35). So my objective would be 9h30 at Nice full ironman in 3 years (2024). 9h30 will rank you 22th, 21th, 21th, 10th in the last years.
Training strategy
There are 5 sports in an ironman, the swim, the bike, the run, the nutrition and the transition (In reality transition is only a thing in short distance triathlon so I didnt prepare it at all). Nutrition is a super important part, you can neglect eating and drinking when you do sport for 9h
In general I also didnt want to do another triathlon before my ironman. Many people say it is suicide to go to an ironman without having done a triahtlon prior, but I don't see a point for it, you dont have to live something to be prepared for it, of course it is better, but you need to prepare also for peeing on the bike ? for drinking salt walter ? for running after 180km bike leg ?
Mentally I like when I have maximum pressure to perform, and training for 3 years and then poping at an ironman without real world experience is something that helped me mentally during all the preparation. It prevent me to really know my level, and telling me I have another chance. I just wanted to perform on that day and let my body and mind no there is no other day to perform, so no triathlon before (My coach was not fan of it at all but well)
My overall plan was:
-
First year : build general fitness, just do running, and cycling to make my body adapt to a high level of training, stress and organize my life to work around it. I don't care about following a program or anything, just do the hours
-
Two next years: take a coach to give me a program and follow it to each details
-
Last 2 months: memorize the bike course to gain as much time in the dowhnill and pace my effort well on each uphill
I averaged 16h of sport per week in the last 2 years. 10h on the bike, 4h on the run and 2h swimming.
The general methodology of ironman training is you have to do a lot of volume at low intensity and when you do high intensity you should not kill yourself, because it is very likely that there is another session in less than 12h and the worst thing that can happen to you is an injury. Then sleep a lot, eat a lot and repeat, this is very stupid
Bike
The first year of my training I was doing too much intensity, I was tired all the time, I was injured very often. I didnt know how to train for bike, and it seems like bike training is pretty siimple:
Do a lot of low intensity ride, do a little bit of intensity each week. Repeat
I was doing 10h of bike per week: 2 x 1h30 + 2x2h + 1x3h
The core of the cardio training will be on the bike, it creates less constraint on the body than running
Most of training was done on low cadence, because thats my natural cadence (about 60rpm). 90% of my bike training was done on the home trainer, for several reasons:
-
Mentally the home trainer is much harder than an outdoor bike ride. Building your mental is very important to not crumble under pression in the race day
-
It is harder physically as there is no rest never, if you stop pedaling the bike stop, so your muscles learn to output a constant force for long duration of time
-
It is much more practicall to do, no need to prepare, no impact of weather forecast etc
Zone 2, is low intensity, it is an intensity that you can maintain without effort for several hours, you can discuss at that pace, you can breathe with your noose. You can find that pace with your cardiac freqency , but in my opinion it is important to learn all your intensities with your feelings, so do not look at your watch every minute
Monday : 1h30 zone 2
Tuesday : 1h30 zone 2
Thursday: 1h30 zone 2 + about 30minute at high intensity
Saturday: 2h zone 2
Sunday: 2h zone 2 + 1h tempo
30min high intensity is something like 4 x 5min at 110% FTP to small interval variation: 3x8x3" at 140% ftp. I dont think what you do really matters, you need to a do a little bit of every kind of intervals between 30" to 5', I followed thorougly what my coach gave me but it didnt feel like it was rocket science
1h tempo is more like 3x15min at 90% ftp or 10-15-20min at 80-85-90% ftp
I felt like my cadence was limiting me so I also forced myself to do some training at high cadence, until 110rpm (It took about 3 months, from not being able to sustain more than 75rpm to be able to sustain 110rpm during one hour). I've read a lot of things about cadence, I believe what is important to master all kind of cadence and then let the natural flow goes on race day
At the end of the prepa I did do a few very long ride, one 200km, and also 3 times the 170km course. But I dont think I did more than 7 times a longer than 4h session
There is a lot of downhills on the Nice track, so I went there and tried to memorize the track to be able to go the fastest as possible (I wanted to have the best time of the last descent over everyone)
I also started to do a lot of the sessions in the aerodynamic position in the last 6 months
Run
Run training is same pretty easy: a bit of cardio training and bit of intensity
I believe I'm naturally gifted for the run so I didnt try to do too much training
I did 4 session of 1h more or less and extended the distance of one run at the end of the prepa
Tuesday: 1h high intensity
Wednesday: 1h zone 2
Saturday: 1h tempo after the zone 2 bike
Sunday: 1h zone 2
For tempo and high intensity it is the same thing than for the bike
I increased the run duration at the end of the prepa. the sunday run was 1h15, then 1h30, then a few times 1h50 but same thing that the bike. I did 3 sessions at more than 1h40 in the whole prepa
Swim
Swim is more complex, it is the only sport that involves techniques.
I initially thought swimming could be my strenght but after training for a few sessions, I hated it, was bad at it, didnt improve much and forced me wake up very early to swim in a swimming pool that is not crowded, so I more or less gave up on the swimming.
I did 2 sessions per week. It was mostly endurance swiming, just swimming during 1h each. I have very low flexibility (I cant lift my arm above my head) and I have low flotability (If I fill my lungs with air and put myself in a swiming pool I sink at the bottom of the pool). So I'm clearly not gifted for this sport despite having a strong back. Actually muscles are almost useless for enduring swimming.
I spend 1 year only swimming with TWO pull buoy to become more flexible in my shoulders. After 1 year I managed to lift my arms above my head (I also did some stretching 2 times a week)
Then I followed a more complex swimming training that my coach was giving me, swiming with hand paddles, kick board, I bought 4 pairs of goggles (and I finally bought custom made ones), backstrokes, breaststrokes etc. I followed everything but never manager to really improve my pace, my best time for a 100m is 1:35, so a very shitty time.
I knew that my race expected time of 1h would be impossible to achieve
Nutrition
For the nutrition my plan was clear. A lot of pro say that the maximum you can eat the best you will perform. So I fixed my goal to 100g of carbs per hour.
I searched for food that I could eat in high quantity and that I my body could digest. I first tested Mars bars but I couldnt eat as much as I wanted after 2 hours. So I settled on Harribo dragibus. On each of my bike ride I would eat 100g of carbs of Dragibus per hour. My body was able to eat that for 5 hours and then it started to become a problem, so I would just reduce the quantity a little bit on the last hour

The second parameter is what you eat off training. My strategy was to eat the maximum as I could all the time, and try to eat a lot of fat, so eating 4 times per day and sleeping 8 hours per night
Race day
I didnt do anything special the weeks before the race, I didnt reduce much the training volume, the week of the ironman I did 5h of bike, 3h of running and the week before 6h of running and 14h of bike.
I ate more sugar than usual the day before the race, but thats about it.
I slept well the night before, ate some rice and then went to the departure
I was stressed of two things:
-
I was afraid to have a puncture on the bike
-
I was afraid they would cancel the swim
So I was tubeless on the bike, so I inflated my tires the morning of the race and that was good. On my bike, I had 3 bottles of water of 800ml + 650g of dragibus. My bike is a Cervelo P5 with a full rear disk

Swim
My tri suit is the Van Rysel trisuit, I didnt want to swim with a combinaison so I swim with only the tri suit, I was afraid to overheat. My goal was to do 1h10, so I started almost 20minutes after the first triathletes. The swim was painfull I never swam for more than 1h or such a long distance, I drank several time sea water, the sea was super agitated and cold, I never swam in open water before. So I felt like it would never end.
I finished in 1:11:20, (1:48/100m) time that I'm happy with, and I dont think I could have done better, I leave the water in 723th position of 2048
My first transition is without any structure, I had to brulure in shoulder and I had to put some lotion. I didnt have to remove my combinaison I have the 298 time, 3 minutes longer than the fastest, clearly a failure, but I loose a lot of time
Bike
Then the bike, My objective was 5h20. My estimate in watt was 240 watts on the flat, and 270-280watt on the uphills. I'm 1m77 and 76kg
I thought I would have an advantage on the beginning of bike because I would just pass everyone and then would benefit from drafting, but in truth it was a shitshow, there were people everywhere, we would sometimes be 4 or 5 abreast. And there is only 9 kilometers of flat (243watt average, 40.5kmh), then it going up and there were people everywhere I had to shout to get people to let me go through. A lot of people didnt know to pace themselves on the first uphill
After 27.8km I was already 241th, after 48km I was 175th. Then there was some downhill, some people would be so slow and be in the middle of the road, I had to pass them from their right.
Then it was the biggest dowmhill, 18km a 5% (900m d+ 271watt). Then some rolling roads (40km at 142 watt 35kmh) I starting getting a cramp at 140km, but managed to continue without much issue. I did the last uphill at 272watt average (for 25minutes) I caught the last pro women at the beginning of the downhill.
I didn't manage to do the best time of the downhill, only did second, also lost my reparation kit on a speed bump. (compared to a guy that finished with the same time as me for the bike, I did 4min30 less than him and hold for 30 more watts)
I managed to do 258 watt average on the last 20km of the bike and did 248 watt average on the whole course and cadence 80rpm
I did the 27th time of the bike, 16minutes after the 2nd time, I let my bike down in 51th position (Only one pro women ahead of me, lucy charles) finished 5h11 (32.8kmh average). 9 minutes less than the objective. I didnt had the chance to ride behind someone, so no gain from drafting as nobody was at my speed the entire course
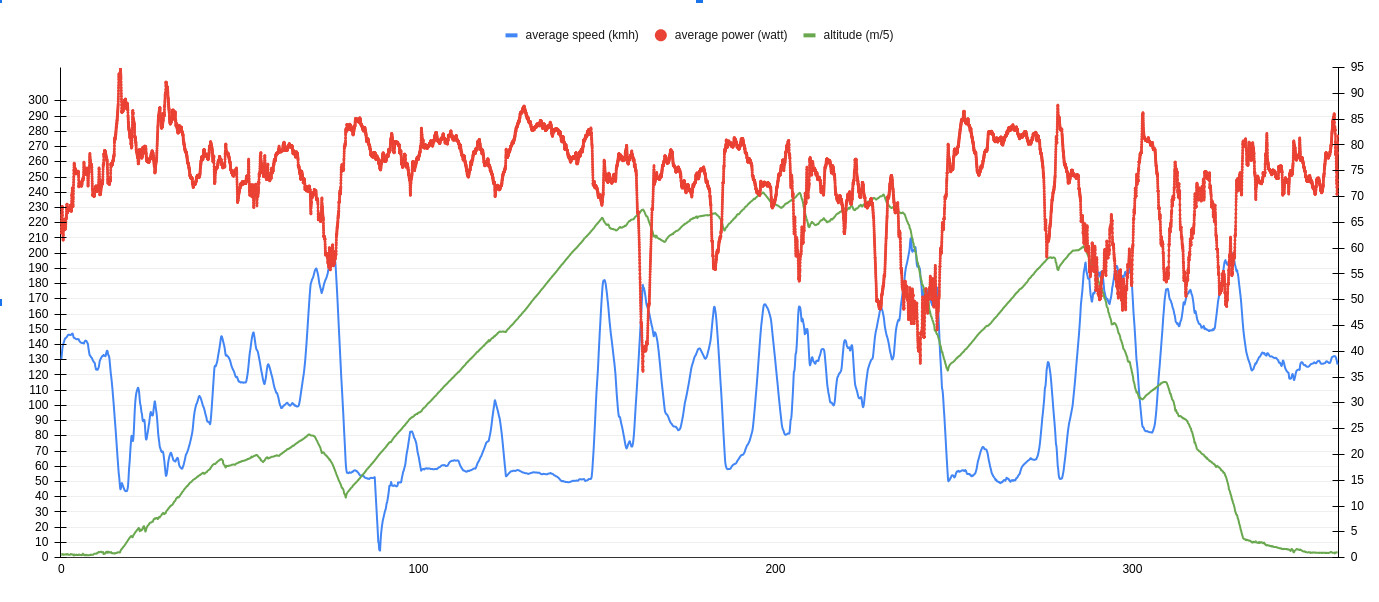
My T2 is the 124th time, 1min 30 more than the first. I failed my transition, I forgot to pee in the downhill. I peed once after 2h of the bike and so I had to stop during the T2 to pee
Run
Then the run, my objective was sub 3h ( the run course is only 41.5km). My plan was to do 4:15 until the 25th km and then accelerate. I had amazing legs at the beginning, I was running at a 4:05 pace and was wondering how it could be so easy, I thought my watch was broken, but after 5km I saw that the pace was right, so I decreased to 4:15. the first 2h went very well I did 2h at 4:16 and then I blow up.
I was a bit overheating on the run, it was hot during that day, and I know that after long effort my body struggle to thermoregulate itself. I still tried to ingest as much water as possible, and to cool down and it more or less worked
I had cramps everywhere on both my legs, on my arms, I couldnt lower my temperature anymore. The last 10km was done at 4:56 pace and finished the "marathon" with a 3:03 time (4:27per kilo average) , 28th time, 30 minutes after the first guy

Final time is 9:36, 32th
I did everything I could on race day, I was on track to do 9h30 and failed in the last hour even though my body had it inside it. That's frustrating.
What could I have done better
-
I Fucked up my two transitions, the second one made me loose 1minute, I should have peed in the last downhill. The first one I spent two minutes just puting cream on my feet to avoid blisters (which I didnt finally got, so it was maybe wortfull but still lost 2 minutes)
-
I didnt do strength training during my prepa. I have neglected strength training, but I feel like I should have made a few session to strengthen my weak parts (I was often feeling tired in the abductor muscles for example)
-
I had cramps at the end of the run, on one side I feel bad about it, because it made me loose 5 or 6 minutes, but on the other hand I have no idea what could have prevented it, and I still gave everything I had on the race day. I drank enough during the race, I didnt overheat not overeat or undereat. I probably lost too much salt and didnt ingest any. We will never know but that one made me loose at least 10minutes
-
I think I could have pushed more power on the climbs, I finish at 250watt average and 250watt on the last legs, I could have put 10 more watts on the uphills, and maybe gain 1min, but I was never able to come close to these number during training, so how to know ?
-
I could have been lighter, I was super fit but I could have lost more upper body muscles, but I chose not to, maybe a few minutes wasted
-
But what is the most disapointing is the swim, I loose about 15min on people around me, I would have been 14th just being a better swimmer. But well I was serious at the traning sessions, just I hated it and never made progress
Next
After the race I was disapointed and wanted to retry the race next year and decrease my time by 20minutes. But I got injured shortly after and loose a few months of training, also I didnt really have the motivation to do one again and carrying theses sacrifices in my life. So I decided to switch objectives.
Now time for my next two objectives, achieve in the next 18 months :
-
Sub 2h30 in a marathon
-
Top 50 world in HYROX PRO ( probably need to do sub 55min)